

Today we're open sourcing Modelplane, a control plane for AI inference. You install it in your own environment, and it operates your GPU clusters as one inference fleet: provisioning clusters, placing models across them, autoscaling replicas, caching weights, and routing requests through a single OpenAI-compatible gateway.
It's built on Crossplane, and it runs any model on any serving engine on any infrastructure, from a single GPU to disaggregated, multi-node serving.
The shift toward open inference
Open-weight models changed who runs AI. They can be post-trained, including with reinforcement learning, to compete with frontier models, and they put cost, governance, and data sovereignty back under your own control. So inference is moving outward, from the labs and hyperscalers that served everyone through an API to a much larger population of organizations running it on their own hardware: neoclouds turning it into a business, regulated and sovereign enterprises keeping it inside their own walls, and AI-native companies bringing their inference bills under control.
The open source community moved fast to meet this, with projects emerging at every layer: serving engines like vLLM, SGLang, and TensorRT-LLM; schedulers, gateways, and routers; and multi-node serving and weight distribution. And Kubernetes is emerging as the convergence point underneath all of it. The cloud-native community is making it a first-class platform for AI workloads, the major inference projects are standardizing on it, and neoclouds like Baseten and CoreWeave run their operations on it.
Inference is a fleet problem
Almost all of those open source projects, though, focus on serving inference within a single cluster, and inference almost never stays in one. Capacity is scattered across hardware types, providers, and regions, sovereignty and compliance pin workloads to particular places, and large clusters concentrate failure. So inference quickly grows into a fleet, and the hard problems move above the cluster: placing models across the available capacity, failing over across clouds and regions, routing by cost and sovereignty, provisioning capacity, and caching and moving weights, all managed as one inference platform.
The labs, the hyperscalers, and the managed providers have all built a system to do this, and they've all built it privately. The open one didn't exist.
Introducing Modelplane
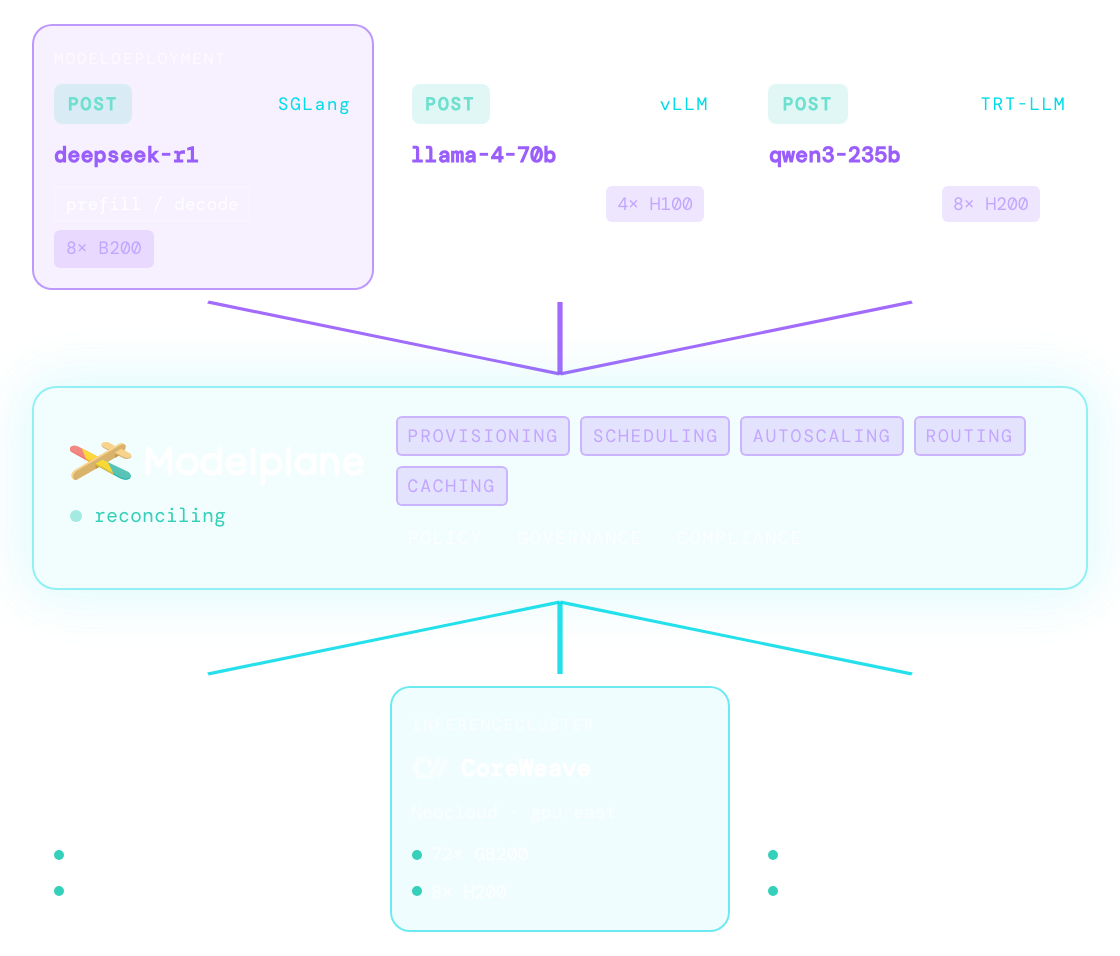
This is why we built Modelplane. We've been watching Crossplane adopters build inference platforms across clusters and operate it at large scale, composing the clusters, the GPUs, the serving stacks, and the routing into their own control planes. We wanted to standardize those patterns, make them far easier to get started with, and contribute the result back to the community as open infrastructure.
Modelplane sits above your inference clusters and operates them as one inference platform, reconciling the whole fleet toward the state you declare. It does for the fleet what Kubernetes does for the cluster: platform teams and developers describe what they want as Kubernetes resources, and Modelplane composes the clusters, places the models, and exposes the endpoints to match.
Modelplane API
The Modelplane API splits along the two teams that actually do this work, and fills in everything between them.
Platform teams define the inference platform. They describe the unified entry
point (an InferenceGateway), the hardware shapes they offer (an
InferenceClass), and the clusters that make up the fleet (an
InferenceCluster), and Modelplane provisions and reconciles them:
apiVersion: modelplane.ai/v1alpha1
kind: InferenceClass # a hardware shape
metadata:
name: gke-l4-1x
spec:
provisioning:
provider: GKE
gke:
machineType: g2-standard-8
accelerator: { type: nvidia-l4, count: 1 }
devices:
- name: gpu
claim: DRA
driver: gpu.nvidia.com
count: 1
capacity:
memory: { value: "23034Mi" } # the L4's usable VRAM
---
apiVersion: modelplane.ai/v1alpha1
kind: InferenceCluster # a cluster in the fleet, provisioned or BYO
metadata:
name: starter
labels:
modelplane.ai/region: us-central
spec:
cluster:
source: GKE
gke: { project: my-gcp-project, region: us-central1 }
nodePools:
- name: gpu-l4
className: gke-l4-1x
minNodeCount: 1
maxNodeCount: 2
---
apiVersion: modelplane.ai/v1alpha1
kind: InferenceGateway # the unified, OpenAI-compatible entry point
metadata:
name: default
spec:
backend: Traefik
traefik:
version: "40.2.0"ML and development teams deploy models. They declare a ModelDeployment (the
model, its engine, serving topology, and a replica count) and a ModelService to expose it as one
stable, OpenAI-compatible endpoint:
apiVersion: modelplane.ai/v1alpha1
kind: ModelDeployment # the model to serve
metadata:
name: qwen-demo
namespace: ml-team
spec:
replicas: 1
engines:
- name: qwen
members:
- role: Standalone
nodeSelector:
devices:
- name: gpu
count: 1
selectors: # any GPU with >= 20Gi VRAM
- cel: device.capacity["gpu.nvidia.com"].memory.compareTo(quantity("20Gi")) >= 0
template:
spec:
containers:
- name: engine
image: vllm/vllm-openai:v0.7.3
args: ["--model=Qwen/Qwen2.5-0.5B-Instruct"]
---
apiVersion: modelplane.ai/v1alpha1
kind: ModelService # one OpenAI-compatible endpoint
metadata:
name: qwen
namespace: ml-team
spec:
endpoints:
- selector:
matchLabels:
modelplane.ai/deployment: qwen-demoThat's the whole interface. Developers never name a cluster: they describe the hardware a replica needs and Modelplane's scheduler places it on a cluster and pool that fits, then hands off to that cluster's own scheduler and DRA to bind the GPUs. Engine flags pass through verbatim, so any container-based engine and any topology works without a change to Modelplane.
Modelplane capabilities
Once those resources exist, five things run continuously across the fleet:
- Provisioning. Create clusters and GPU node pools on hyperscalers, neoclouds or bring your own on any Kubernetes, and install the serving stack on each.
- Scheduling. A two-level scheduler places each replica on a cluster and pool whose hardware matches using DRA and cel expressions, accounting capacity at the node level so it never overcommits.
- Autoscaling. Scale replicas through the standard Kubernetes scale
subresource, so
kubectl scaleand a KEDAScaledObjectwork out of the box. - Routing. One OpenAI-compatible
ModelServiceover many replicas, with weighted traffic for canary and A/B rollouts and optional fallback to an external provider. - Caching. Stage model weights on cluster storage once, so serving pods read them locally instead of re-downloading on every start.
Modelplane stays neutral across models, engines, accelerators, clouds, and serving stacks, and composes them rather than replacing them.
We're building in the open
Modelplane is early, and we're releasing it at v0.1 so we can build it in the open, with the community. It's Apache 2, and we plan to donate it to a neutral open source foundation later this year, because a control plane that sits above the ecosystem should belong to the ecosystem.
If you're running inference yourself, planning to, or hosting accelerators (any vendor, any cloud, on-prem), we'd love for you to join us. Modelplane is live at github.com/modelplaneai/modelplane, with a getting-started guide at docs.modelplane.ai/getting-started that takes you from nothing to a live endpoint in about 45 minutes. Come find us in the Kubernetes Slack (#modelplane), open issues, contribute, and help us shape it.
Kubernetes became the standard control plane for compute. With Modelplane, we’re extending that same approach to AI inference across fleets of cloud, neocloud and datacenters.
Intelligence is becoming the most important thing we build, and it shouldn’t be something you can only rent. Everyone should be able to own theirs.
Help us build that future.